This is an open access paper.
AJHG http://dx.doi.org/10.1016/j.ajhg.2015.03.012
The Kalash Genetic Isolate: Ancient Divergence, Drift, and Selection
Qasim Ayub et al.
The Kalash represent an enigmatic isolated population of Indo-European speakers who have been living for centuries in the Hindu Kush mountain ranges of present-day Pakistan. Previous Y chromosome and mitochondrial DNA markers provided no support for their claimed Greek descent following Alexander III of Macedon's invasion of this region, and analysis of autosomal loci provided evidence of a strong genetic bottleneck. To understand their origins and demography further, we genotyped 23 unrelated Kalash samples on the Illumina HumanOmni2.5M-8 BeadChip and sequenced one male individual at high coverage on an Illumina HiSeq 2000. Comparison with published data from ancient hunter-gatherers and European farmers showed that the Kalash share genetic drift with the Paleolithic Siberian hunter-gatherers and might represent an extremely drifted ancient northern Eurasian population that also contributed to European and Near Eastern ancestry. Since the split from other South Asian populations, the Kalash have maintained a low long-term effective population size (2,319–2,603) and experienced no detectable gene flow from their geographic neighbors in Pakistan or from other extant Eurasian populations. The mean time of divergence between the Kalash and other populations currently residing in this region was estimated to be 11,800 (95% confidence interval = 10,600−12,600) years ago, and thus they represent present-day descendants of some of the earliest migrants into the Indian sub-continent from West Asia.
Link

Showing posts with label Pakistan. Show all posts
Showing posts with label Pakistan. Show all posts
April 30, 2015
November 15, 2012
Swat valley cemetery
A lost civilisation: 3,000-year-old cemetery discovered in Swat
The Italian Archaeological Mission on Wednesday discovered an ancient cemetery dating back thousands of years at Odigram, Swat — a site experts believe was built between 1500 BC to 500 BC.
...
A total of 23 graves have been excavated at the site that seems to be an ancient cemetery, indicating that they belonged to the pre-Buddhist era.
...
“It clearly indicates that Swat Valley was thickly populated at that time. Most probably they were the Dards (a group of people defined by linguistic similarities and not a common ethnic origin, predominantly found in Eastern Afghanistan) and in my view these Dards were somehow linked culturally to the people presently living in Kohistan and Kalash valleys,” revealed Massimo Vidale, a professor of Archaeology at University of Padua. “They probably spoke the Indo-European languages. We can say that the present culture of Kalash and Kohistan in Chitral valley can be linked with the ancient culture of Swat,” Vidale explained.
September 24, 2012
rolloff analysis of French as a mixture of Sardinian+Burusho
I obtain f3(French; Sardinian, Burusho) = -0.002652 (Z=-13.541) on the basis of 446,917 SNPs. This is the strongest signal of admixture in the French that involves a population that is high on the "West_Asian" component whose influence I have been investigating.
I thus carried out rolloff analysis using the French as a target population and the Sardinians and Burusho as reference populations. The exponential fit can be seen below:

The jackknife gives 239.556 +/- 50.553 generations for this admixture, which corresponds (assuming a generation length of 29 years) to 6,950 +/- 1,470 years.
Analysis of autosomal DNA from the Tyrolean Iceman and a Neolithic TRB farmer from Sweden have revealed an absence of the West Asian ancestral component and a Sardinian-like Neolithic population c. 5ka in Europe. This population may have extended to at least to the Balkans in space and down to the Iron Age in time.
In my opinion, the simplest explanaton for the evidence is that the admixture picked up by rolloff took place in West Asia itself c. 7ka, and then this population begun its movement into Europe at some post-5ka time period.
Importantly, the K=12 Caucasus component appears as a mixture of the K=7 West_Asian and Southern components. The former (West_Asian) is the most important one in the Burusho, and the latter (Southern) is the most important one in Sardinians.
European Neolithic farmers, of presumably West Asian origin only possessed Y-haplogroup G2a out of the wide variety of haplogroups found in West Asia today. They also lacked the West_Asian component which is modal in West Asia today. There is also physical anthropological evidence from Greece and Anatolia, for an introduction of new population elements during the Bronze Age.
These facts combine to make me believe that there were population movements across West Asia which preceded the Indo-European invasion of Europe during late pre-history. That event is then best seen as an extension of a broader Eurasian phenomenon that affected substantially both the western parts of Asia and Europe.
 Taking all the evidence into account, I hypothesize that:
Taking all the evidence into account, I hypothesize that:- a "Southern"/"Atlantic_Med"/Sardinian-like population substratum existed in West Asia, and this spawned the early European Neolithic.
- a new "West_Asian"/Burusho-like population arrived from the east, perhaps associated with the Halaf/Hassuna cultures, or from some other unknown center of dispersal in the Transcaucasus or Iran. Mobility may have been encouraged post-8.2 kiloyear event.
- these two elements began mixing ~7 thousand years ago in West Asia
- the admixed population expanded at some post-5ka period into Western Europe.
(Obviously, more rolloff analyses are needed to study these ideas; the current one took about ~3 days, which was a little faster than I expected.)
Related (?): Is Burushaski Indo-European?
Image credit: Don Perrault (source)
December 08, 2011
Population structure in South Asia (Metspalu et al. 2011)
 I haven't read the paper fully yet (it's open access), but the abstract seems to agree with what I've written both here and over at the Dodecad blog, about South Asians being primarily a West Asian/South Asian variable mix. I will try to get and analyze the new data from the paper; it is strange that every time I am just about ready to release the new version of Dodecad v4, I discover a source of new data!
I haven't read the paper fully yet (it's open access), but the abstract seems to agree with what I've written both here and over at the Dodecad blog, about South Asians being primarily a West Asian/South Asian variable mix. I will try to get and analyze the new data from the paper; it is strange that every time I am just about ready to release the new version of Dodecad v4, I discover a source of new data!The American Journal of Human Genetics, Volume 89, Issue 6, 731-744, 9 December 2011
Shared and Unique Components of Human Population Structure and Genome-Wide Signals of Positive Selection in South Asia
Mait Metspalu et al.
South Asia harbors one of the highest levels genetic diversity in Eurasia, which could be interpreted as a result of its long-term large effective population size and of admixture during its complex demographic history. In contrast to Pakistani populations, populations of Indian origin have been underrepresented in previous genomic scans of positive selection and population structure. Here we report data for more than 600,000 SNP markers genotyped in 142 samples from 30 ethnic groups in India. Combining our results with other available genome-wide data, we show that Indian populations are characterized by two major ancestry components, one of which is spread at comparable frequency and haplotype diversity in populations of South and West Asia and the Caucasus. The second component is more restricted to South Asia and accounts for more than 50% of the ancestry in Indian populations. Haplotype diversity associated with these South Asian ancestry components is significantly higher than that of the components dominating the West Eurasian ancestry palette. Modeling of the observed haplotype diversities suggests that both Indian ancestry components are older than the purported Indo-Aryan invasion 3,500 YBP. Consistent with the results of pairwise genetic distances among world regions, Indians share more ancestry signals with West than with East Eurasians. However, compared to Pakistani populations, a higher proportion of their genes show regionally specific signals of high haplotype homozygosity. Among such candidates of positive selection in India are MSTN and DOK5, both of which have potential implications in lipid metabolism and the etiology of type 2 diabetes.
Link
May 08, 2011
On the northern/southern Caucasoid contributions to Asia
I project a great number of Siberian, Central Asian, and South Asian populations on the first two principal components created by Han, West Asians, and Northern Europeans.
PC1 captures east-west variation across Eurasia, although the Han are also related to Ancestral South Asians, a major component in the ancestry of South Asians. PC2 captures West Asian-North European variation, so it is quite useful to extract the relative northern vs. southern Caucasoid elements in the populations examined.
Here are the first two PCs with the populations used to create them. Northeastern European (N=49) includes Lithuanians, Belorussians, Russians, Poles, and various non-Balkan Slavs. Northwestern European (N=46) includes Germans, Irish, Norwegians, and various continental Germanics. West Asian (N=93) includes Armenians, Iranians, Adygei, Lezgins, and Georgians.

Population labels are always placed on population averages. Notice that the Han form a tight cluster, halfway (along PC2) between West Asians and Northeast Europeans; this is expected as they are an outgroup that has not been significantly affected by Caucasoids.
We will now project various populations onto the previous 2-D map: their horizontal position (along PC1) depends on the extent of Caucasoid admixture, while their vertical position (along PC2) depends on whether this admixture is more northern or southern Caucasoid.

UPDATE (May 9):
I have also carried out supervised ADMIXTURE analysis, using the dataset of this post, adding Onge from the Indian Ocean as a fourth ancestral group together with Han, Northern Europeans, and West Asians.

The results seem consistent with the PCA projection, while the distinctiveness of the East Asian (dark blue) and Ancestral South Indian (light blue) components emerges.
May 07, 2011
Beware of sample sizes: why Ancestral North Indians came from West Asia, not Eastern Europe
In the previous two parts of my trilogy, I presented the evidence for the clear West Asian origin of the bulk of South Asian Caucasoid ancestry. There was one thing that nagged me, however: Reich et al. (2009) had presented evidence (based on their 4-population test) that Ancestral North Indians formed a clade with CEU White Utahns at the exclusion of the Adygei from the Caucasus. This seemed inconsistent with my theory, and I considered many potential solutions to the problem, until I recently realized what was happening.
A good way to determine whether ANI is more similar to CEU or to Adygei is to calculate the first principal component of variation between CEU and Adygei, and then project the Indian Cline samples onto it. Since these samples are composed of an Onge-like South Indian component (outgroup) and a Caucasoid factor X, their position on PC1 of CEU vs. Adygei will be determined by the relationship of X with either CEU or Adygei.
Here are the results:
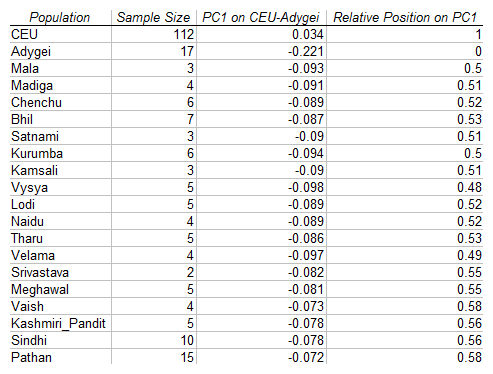
Notice that many populations are around the 0.5 mark between Adygei and CEU, i.e., they are not particularly closer to one population than the other. But, a few of them, notably Pathans and Kashmiri Pandits are closer to CEU than to Adygei.
Now, consider the following table (Note S3 Table 1) from Reich et al. (2009):

This is the evidence, based on the 4-population test that CEU and ANI form a clade. Notice that this is based on comparisons with Pathans and Kashmiri Pandits, i.e., with two groups that seem to deviate towards CEU in the PC1 projection. Indeed, only for the Pathans (the most CEU-like group) is the Z-score more than 3, the condition considered necessary for statistical significance. We can thus conclude that ANI is not in general a clade with CEU. This may be true only for the most CEU-like South Asian populations, but it is not generally true.
Now, we will see that it is not true even for the most CEU-like South Asian populations.
Clearly, the PC1 projections presented above hint why the evidence for CEU-ANI forming a clade is stronger for Pathans and Kashmiri Pandits. But, they seem to go against all the data I presented in my earlier two posts about the main West Asian origin of Ancestral North Indians. If that were true, then we would expect Ancestral North Indians to be projected closer to Adygei (0) rather than in the middle (0.5), or towards CEU (1).
I puzzled long about why this was the case, considering inter alia: that Adygei were not a good representative of West Asians, that ASI was not a true outgroup, or that I was wrong. All of these explanations failed, until I realized the true culprit: uneven sample sizes of Adygei and CEU.
Let's repeat the PC1 projection, but using a 17-person random sample from CEU, so that Adygei and CEU have equal sample sizes.

Unexpectedly, now all Indian Cline populations are clearly shifted towards the Adygei side of the CEU-Adygei PC1, and the results are compatible with the idea of the mainly West Asian origin of ANI.
It's not entirely clear to me why this is happening, without dissecting the results. Here is my tentative guess: CEU and Adygei populations both possess low-frequency West Eurasian variants that are absent in the smaller Adygei sample, but present in the much larger CEU one. When one of these variants pops up in an Indian Cline sample, it is mistaken for a CEU variant. By equalizing sample sizes, CEU does not have an edge over Adygei at including low-frequency variants, hence this bias is removed.
I have also carried out another experiment substituting CEU with 10 Lithuanians and 9 Belorussians from Behar et al. (2010) and Adygei with 19 Iranians from the same.
Any northern European component in Indians is likely to be more similar to eastern Europeans than to CEU, which is mainly of northwestern European origin. Also, I did not use Russians, as their low-level East Eurasian admixture might have altered them somewhat compared to the putative ancestors of the Indo-Aryans who lacked such eastern Asian influences.
I chose Iranians, as they are the linguistic cousins of the Indo-Aryans, and also happened to have a convenient sample size of 19 that was equal to the sum of Belorussians+Lithuanians.
Here are the results:

And another experiment using Hungarians as a Central European sample:

I have also carried out the same experiment using CEU17 and Iranians:

There you have it: clear evidence that the Ancestral North Indian component is more closely related to West Asians than to N/C/E Europeans.
Conclusion
To cut a long story short:
- CEU and ANI do not form a clade: the evidence for this clade is based on the most CEU-like Indian Cline populations, and even in their case it is an artefact of unequal sample sizes
- ANI is most similar to people from West Asia rather than Eastern Europe
January 04, 2011
A genetic map of Pakistan
Here is a multidimensional scaling plot of 9 different populations of Pakistan I've collected in the Dodecad Project. The "Pakistani" population from Xing et al. (2010) consists of Arain agriculturalists from the Punjab region.

It is fairly obvious that there are 5 clusters in these first two dimensions, and GALORE analysis confirms it:
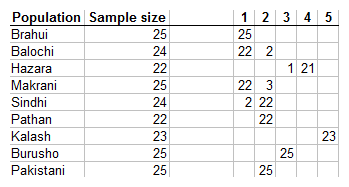
The isolated Kalash form cluster #5, and the part Mongoloid Hazara #4. The Burusho are a genetic and linguistic isolate, falling in cluster #3. The other 2 clusters comprise of multiple populations: Cluster #1 the Brahui, Balochi, and Makrani and could very well be termed "Balochistan". Cluster #2 comprises of the Sindhi, Pathan, and Punjabi samples.
UPDATE:
Here are two additional MDS plots. In the first one the Kalash have been removed; in the second one both the Kalash and the Hazara:


March 04, 2008
AAPA 2008 abstracts
The 2008 meeting of the American Association of Physical Anthropologists will take place this April, and the book of abstracts for the conference is online in pdf format. As usual, there is a great variety of exciting research to be announced in the meeting; here is my sampling thereof:
A seemingly very important new piece of work on Central Anatolia:
O. Gokcumen et al., The Land of the Tired Ox: Ethnogenetic Insights into Rural Central Anatolian Population History
I can only hope that more researchers will look into historical processes that have shaped modern populations. Too often I see research published which tries to infer human prehistory from modern populations, seemingly oblivious to the complex set of events in historical time that have shaped these populations. Anatolia, so often discussed in the context of the origin of the Neolithic is a prime example of this, as it contains multiple layers of population settlement and ethnic change.
M. C. Dulik et al. Y-chromosome variation in Altaian ethnic groups
L. Pipes et al. Analysis of mtDNA in Mongolian Populations
J. Hawks. "Adaptive evolution of human hearing and the appearance of language"
B.E. Hemphill. Are the inhabitants of Madaklasht an emigrant Persian population in northern Pakistan?: a dental morphometric investigation.
Someone should look at their genes. Human history is a giant jigsaw puzzle and it is populations that differ from their neighbors and came from somewhere else that allow us to catch a glimpse of the past (in this case prehistoric Central Asia).
N. Seguchi. "Re-analysis of the ainu-samurai hypothesis using population genetic analysis."
A seemingly very important new piece of work on Central Anatolia:
O. Gokcumen et al., The Land of the Tired Ox: Ethnogenetic Insights into Rural Central Anatolian Population History
Excerpt: "For example, in one study area in the vicinity of Ankara, we have observed at least four distinct groups based on historical and ethnographic observations. Their self-claimed ancestries trace back to Afsar, Kurdish, Caucasian Cherkess, and Karaman groups. These groups came into the same area from different source regions and at different moments in history. Indeed, our data indicate that there were significant disparities between the paternal and maternal genetic diversity among these groups. These data also allow us to more accurately reconstruct the population history of the study area, as well as begin to provide new perspectives on the regional history of Central Anatolia in relation to historical Turkic invasions and perhaps the Neolithic transition. Finally, we discuss the utility of a more focal and detailed sampling approach for elucidating Anatolian population history."
I can only hope that more researchers will look into historical processes that have shaped modern populations. Too often I see research published which tries to infer human prehistory from modern populations, seemingly oblivious to the complex set of events in historical time that have shaped these populations. Anatolia, so often discussed in the context of the origin of the Neolithic is a prime example of this, as it contains multiple layers of population settlement and ethnic change.
M. C. Dulik et al. Y-chromosome variation in Altaian ethnic groups
Excerpt: "A large portion of all Altaian haplotypes belonged to haplogroup R. Differences in haplogroup frequency between the northern and southern Altaian populations were also observed, with more individuals from northern groups belonging to haplogroups N and Q, and haplogroup C being more prevalent in southern populations. In addition, there were village level patterns of NRY variation, while the overall diversity of NRY haplotypes suggested a significant cultural influence on the partitioning of genetic variation (i.e., patrilocality)."The three elements involved in Siberian prehistory are indeed haplogroup R, in particular R1a1 which (in my opinion) represents the Western-derived Caucasoid element of likely Iranic affiliation, haplogroups N and Q which represent the Palaeo-Mongoloid element indigenous to Siberia and which has radiated from Siberia to the west (in the case of N) and to the east and into the Americas (in the case of Q), and the Mongoloid proper element which is associated with haplogroup C in this region, and which reflects the Eastern-derived movements of Mongoloid(-influenced) Altaic speakers such as the Mongols.
L. Pipes et al. Analysis of mtDNA in Mongolian Populations
J. Hawks. "Adaptive evolution of human hearing and the appearance of language"
Language requires not only a detailed anatomical and neurological system of language production, but also a highly adapted system of reception. Considering the frequency and amplitude range of human speech, the necessity of perceiving a large number of distinct speakers, the extended life history of humans, the need for children to learn phonemic distinctions at an early age, and the spatial distances covered by vocal communication in humans compared to other primates, it is likely that humans have distinctive auditory adaptations to language. This study tests the hypothesis of selection on the human auditory system, by interspecific genomic comparisons and genome-wide selection scans in living people. A set of hearing-related human genes shows clear signs of recurrent selected substitutions in humans compared to chimpanzees and macaques. These recurrent substitutions may have occurred at any time during human evolutionary history, but they were repeated with several selected variants for each gene. A smaller set of genes shows signs of significant population differentiation within the past 50,000 years, due to recent strong selection. Further, a relatively large set of hearing-related genes have segregating variants under recent strong selection in one or more human populations. These genes reflect continuing selection on hearing within the last 2000—3000 years. Together, these results suggest that human vocal communication exerted repeated selection pressures on the auditory system, that the system of human language continued to evolve during the Late Pleistocene, and that humans may still be adapting to language.It seems that Hawks et al. paper on accelerated recent human evolution was just the beginning...
B.E. Hemphill. Are the inhabitants of Madaklasht an emigrant Persian population in northern Pakistan?: a dental morphometric investigation.
The answer: "Madaklasters share closest affinities to prehistoric Central Asians and more distant affinities to prehistoric inhabitants of the Iranian Plateau. Such results support the claim that the inhabitants of Madaklast are an intrusive population into Pakistan whose origins most likely may be found in northeastern Afghanistan and Tajikistan."
Someone should look at their genes. Human history is a giant jigsaw puzzle and it is populations that differ from their neighbors and came from somewhere else that allow us to catch a glimpse of the past (in this case prehistoric Central Asia).
N. Seguchi. "Re-analysis of the ainu-samurai hypothesis using population genetic analysis."
The conclusion: "The result shows that the Kamakura ties to the Ainu first, before it ties to the other ethnic Japanese. In addition, the Kamakura group shows more variability,indicating that the Kamakura group may have experienced significantly more gene flow. This indicates the Ainu-derived people who lived in East Japan at that time made a genetic contribution to the warrior class of Kamakura."J. K. Rilling et al. "Abdominal depth as a principal determinant of human female attractiveness."
Excerpt: "Multiple linear regression analysis revealed that the depth of the lower torso at the umbilicus, or abdominal depth, was the strongest predictor of attractiveness, stronger than either BMI or WHR, and that its impact was significantly greater for video and side view stimuli in which it was clearly visible compared with front and back view stimuli. Women with shallow abdominal depth are more likely to be healthy, fertile and non-pregnant, suggesting that this may be an adaptive male preference that has been shaped by natural selection."
October 19, 2006
Greek origins of some Pathans but not other Pakistanis

A new article in European Journal of Human Genetics investigates the Greek ancestry of Pakistani populations that sometimes claim descent from Alexander the Great's troops. In previous studies (use search on the right) it was demonstrated that these claims are mostly false, since modern Pakistanis mostly lack haplogroup E3b chromosomes that are found often in Greece.
The new study shows that among the Pakistani populations, only the Pathans seem to be closer to the Greeks, and not the pagan Kalash and the Burusho. Unfortunately, claims about the Hellenicity of the Kalash seem to persist despite the genetic evidence that has accumulated over the years.
Moreover, the similarity between the Pathans and the Greeks is not accidental. An argument for the real contribution of Greeks to the Pathan population is the discovery of specific haplotypes within haplogroup E3b1 that seem to be of Greek-Balkan origin and which are found only in the Pathans among the Pakistani populations.
Compelling evidence in support of the genetic relationship between the Pathan and Greek E3b1 Y chromosomes was provided by the median-joining network (Figure 4). One Pathan shared a Y-STR haplotype, that included a duplication of 10 and 13 repeat units for the DYS425 locus, with three Greek individuals and the other was separated from this cluster by a single mutation, which enabled us to estimate the TMRCA (mean+/-SD) using the Network software as between 2000+/-400 and 5000+/-1200 YBP depending upon the observed26 or inferred mutation rates,27 respectively. This coincides with the period of Alexander's invasion during 327–323 BC. This haplotype was not observed in any other E3b1-derived Pakistani Y chromosome but was highly specific for the Balkans – the highest frequency being in Macedonia.European Journal of Human Genetics (advance online publication)
Y-chromosomal evidence for a limited Greek contribution to the Pathan population of Pakistan
Sadaf Firasat et al.
Three Pakistani populations residing in northern Pakistan, the Burusho, Kalash and Pathan claim descent from Greek soldiers associated with Alexander's invasion of southwest Asia. Earlier studies have excluded a substantial Greek genetic input into these populations, but left open the question of a smaller contribution. We have now typed 90 binary polymorphisms and 16 multiallelic, short-tandem-repeat (STR) loci mapping to the male-specific portion of the human Y chromosome in 952 males, including 77 Greeks in order to re-investigate this question. In pairwise comparisons between the Greeks and the three Pakistani populations using genetic distance measures sensitive to recent events, the lowest distances were observed between the Greeks and the Pathans. Clade E3b1 lineages, which were frequent in the Greeks but not in Pakistan, were nevertheless observed in two Pathan individuals, one of whom shared a 16 Y-STR haplotype with the Greeks. The worldwide distribution of a shortened (9 Y-STR) version of this haplotype, determined from database information, was concentrated in Macedonia and Greece, suggesting an origin there. Although based on only a few unrelated descendants, this provides strong evidence for a European origin for a small proportion of the Pathan Y chromosomes.
Link
September 06, 2006
Shared Y-chromosome heritage of Hindus and Muslims in India
A new study has looked at the Y-chromosome variation of a sample of Hindus and Muslims from Andhra Pradesh, finding them to be similar to each other. This indicates that at least in this case, the transmission of the Muslim religion was largely non-genetic.
Human Genetics (online early)
A shared Y-chromosomal heritage between Muslims and Hindus in India
Ramana Gutala et al.
Abstract Arab forces conquered the Indus Delta region in 711 AD and, although a Muslim state was established there, their influence was barely felt in the rest of South Asia at that time. By the end of the tenth century, Central Asian Muslims moved into India from the northwest and expanded throughout the subcontinent. Muslim communities are now the largest minority religion in India, comprising more than 138 million people in a predominantly Hindu population of over one billion. It is unclear whether the Muslim expansion in India was a purely cultural phenomenon or had a genetic impact on the local population. To address this question from a male perspective, we typed eight microsatellite loci and 16 binary markers from the Y chromosome in 246 Muslims from Andhra Pradesh, and compared them to published data on 4,204 males from East Asia, Central Asia, other parts of India, Sri Lanka, Pakistan, Iran, the Middle East, Turkey, Egypt and Morocco. We find that the Muslim populations in general are genetically closer to their non-Muslim geographical neighbors than to other Muslims in India, and that there is a highly significant correlation between genetics and geography (but not religion). Our findings indicate that, despite the documented practice of marriage between Muslim men and Hindu women, Islamization in India did not involve large-scale replacement of Hindu Y chromosomes. The Muslim expansion in India was predominantly a cultural change and was not accompanied by significant gene flow, as seen in other places, such as China and Central Asia.
Link
Human Genetics (online early)
A shared Y-chromosomal heritage between Muslims and Hindus in India
Ramana Gutala et al.
Abstract Arab forces conquered the Indus Delta region in 711 AD and, although a Muslim state was established there, their influence was barely felt in the rest of South Asia at that time. By the end of the tenth century, Central Asian Muslims moved into India from the northwest and expanded throughout the subcontinent. Muslim communities are now the largest minority religion in India, comprising more than 138 million people in a predominantly Hindu population of over one billion. It is unclear whether the Muslim expansion in India was a purely cultural phenomenon or had a genetic impact on the local population. To address this question from a male perspective, we typed eight microsatellite loci and 16 binary markers from the Y chromosome in 246 Muslims from Andhra Pradesh, and compared them to published data on 4,204 males from East Asia, Central Asia, other parts of India, Sri Lanka, Pakistan, Iran, the Middle East, Turkey, Egypt and Morocco. We find that the Muslim populations in general are genetically closer to their non-Muslim geographical neighbors than to other Muslims in India, and that there is a highly significant correlation between genetics and geography (but not religion). Our findings indicate that, despite the documented practice of marriage between Muslim men and Hindu women, Islamization in India did not involve large-scale replacement of Hindu Y chromosomes. The Muslim expansion in India was predominantly a cultural change and was not accompanied by significant gene flow, as seen in other places, such as China and Central Asia.
Link
June 14, 2006
Y chromosomes of Iran
This is a potentially very important high-resolution Y chromosome study of Iran, which was previously studied only with low-resolution markers.
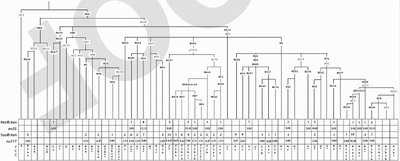
Hum Hered. 2006 Jun 12;61(3):132-143 [Epub ahead of print]
Iran: Tricontinental Nexus for Y-Chromosome Driven Migration.
Regueiro M, Cadenas AM, Gayden T, Underhill PA, Herrera RJ.
Due to its pivotal geographic position, present day Iran likely served as a gateway of reciprocal human movements. However, the extent to which the deserts within the Iranian plateau and the mountain ranges surrounding Persia inhibited gene flow via this corridor remains uncertain. In order to assess the magnitude of this region's role as a nexus for Africa, Asia and Europe in human migrations, high-resolution Y-chromosome analyses were performed on 150 Iranian males. Haplogroup data were subsequently compared to regional populations characterized at similar phylogenetic levels. The Iranians display considerable haplogroup diversity consistent with patterns observed in populations of the Middle East overall, reinforcing the notion of Persia as a venue for human disseminations. Admixture analyses of geographically targeted, regional populations along the latitudinal corridor spanning from Anatolia to the Indus Valley demonstrated contributions to Persia from both the east and west. However, significant differences were uncovered upon stratification of the gene donors, including higher proportions from central east and southeast Turkey as compared to Pakistan. In addition to the modulating effects of geographic obstacles, culturally mediated amalgamations consistent with the diverse spectrum of a variety of historical empires may account for the distribution of haplogroups and lineages observed. Our study of high-resolution Y-chromosome genotyping allowed for an in-depth analysis unattained in previous studies of the area, revealing important migratory and demographic events that shaped the contemporary genetic landscape.
Link
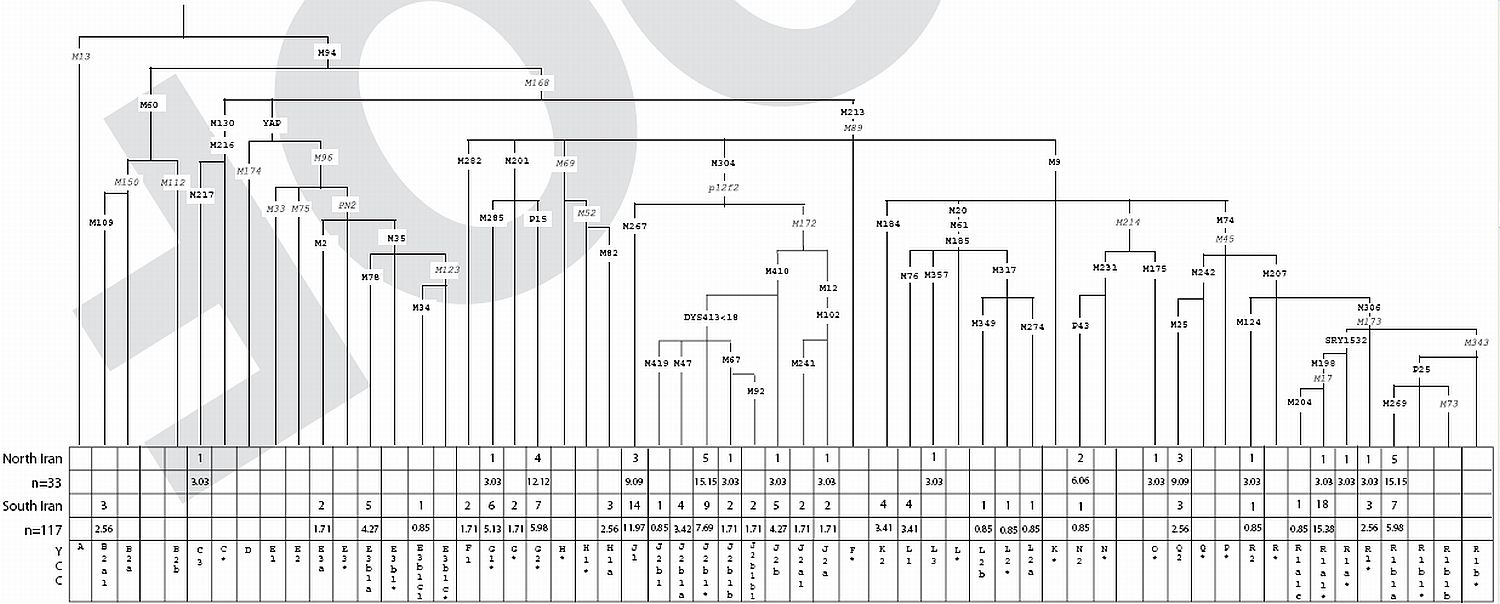
Hum Hered. 2006 Jun 12;61(3):132-143 [Epub ahead of print]
Iran: Tricontinental Nexus for Y-Chromosome Driven Migration.
Regueiro M, Cadenas AM, Gayden T, Underhill PA, Herrera RJ.
Due to its pivotal geographic position, present day Iran likely served as a gateway of reciprocal human movements. However, the extent to which the deserts within the Iranian plateau and the mountain ranges surrounding Persia inhibited gene flow via this corridor remains uncertain. In order to assess the magnitude of this region's role as a nexus for Africa, Asia and Europe in human migrations, high-resolution Y-chromosome analyses were performed on 150 Iranian males. Haplogroup data were subsequently compared to regional populations characterized at similar phylogenetic levels. The Iranians display considerable haplogroup diversity consistent with patterns observed in populations of the Middle East overall, reinforcing the notion of Persia as a venue for human disseminations. Admixture analyses of geographically targeted, regional populations along the latitudinal corridor spanning from Anatolia to the Indus Valley demonstrated contributions to Persia from both the east and west. However, significant differences were uncovered upon stratification of the gene donors, including higher proportions from central east and southeast Turkey as compared to Pakistan. In addition to the modulating effects of geographic obstacles, culturally mediated amalgamations consistent with the diverse spectrum of a variety of historical empires may account for the distribution of haplogroups and lineages observed. Our study of high-resolution Y-chromosome genotyping allowed for an in-depth analysis unattained in previous studies of the area, revealing important migratory and demographic events that shaped the contemporary genetic landscape.
Link
January 05, 2006
J variance in Iran, Pakistan, India, Turkey, and the Balkans
Quintana-Murci et al. reported that the STR variance in haplogroup J is
See also STR variance of haplogroup J2 in the Balkans and Anatolia.
- 0.57 in Iran
- 0.47 in Pakistan
- 0.36 in India
See also STR variance of haplogroup J2 in the Balkans and Anatolia.
November 24, 2005
New paper on Indian Y-chromosome variation
A new paper on Y-chromosome variation in India has become available as an unedited preprint in the AJHG site. This is a huge study which covered linguistic/caste groups from the entire country and used 69 binary markers and 10 microsatellites to create a very thorough sampling of Indian Y-chromosomal variation. It will take some time to digest all the new information, plus the supplemental materials of the paper that remain to be put online. I will blog more about this soon. In bullet form, some findings of the paper which caught my attention:
The samples:

American Journal of Human Genetics (in press)
Polarity and Temporality of High Resolution Y-chromosome Distributions in India Identify Both Indigenous and Exogenous Expansions and Reveal Minor Genetic Influence of Central Asian Pastoralists
Sanghamitra Sengupta, Lev A. Zhivotovsky, Roy King, S. Q. Mehdi, Christopher A. Edmonds, Cheryl-Emiliane T. Chow, Alice A. Lin, Mitashree Mitra, Samir K. Sil, A. Ramesh, M.V. Usha Rani, Chitra M. Thakur, L. Luca Cavalli-Sforza, Partha P. Majumder and Peter A. Underhill
Abstract
While considerable cultural impact on social hierarchy and language in south Asia is attributable to the arrival of nomadic Central Asian pastoralists, genetic data (mitochondrial and Y chromosomal) have yielded dramatically conflicting inferences on the genetic origins of tribes and castes of south Asia. We sought to resolve this conflict using high-resolution data on 69 informative Y-chromosome binary markers and 10 microsatellite markers from a large set of geographically, socially and linguistically representative ethnic groups of south Asia. We have found that the influence of Central Asia on the pre-existing gene pool was minor. The ages of accumulated microsatellite variation in the majority of Indian haplogroups exceed 10-15 kya, attesting to the antiquity of regional differentiation. Therefore, our data do not support models that invoke a pronounced recent genetic input from central Asia to explain the observed genetic variation in south Asia. R1a1 and R2 haplogroups indicate demographic complexity that is inconsistent with a recent single history. Associated microsatellite analyses of the high frequency R1a1 haplogroup chromosomes indicate independent recent histories of the Indus valley and the peninsular Indian region. Our data are also more consistent with a peninsular origin of Dravidian speakers than a source with proximity to the Indus and significant genetic input resulting from demic diffusion associated with agriculture. Our results underscore the importance of marker ascertainment towards distinguishing phylogenetic terminal branches from basal nodes when attributing ancestral composition and temporality to either indigenous or exogenous sources. Our reappraisal indicates that pre-Holocene and Holocene era – not Indo-European – expansions have shaped the distinctive south Asian Y-chromosome landscape.
- R1a1's molecular variance is highest in NW India and its age is substantial
- R1a1's variance is high in tribals
- The phylogeny of J2 has been refined and it is now split into two newly discovered clades, called J2a and J2b.
- J2 is almost entirely absent from tribals and is represented at a higher frequency in upper castes than middle castes than lower castes.
The samples:
High-resolution assessment of Y-chromosome binary haplogroup composition was conducted on 728 Indian samples representing 36 populations, including 17 tribal populations, from six geographic regions and different social and linguistic categories. They comprise (Austro-Asiatic) Ho, Lodha, Santal, (Tibeto-Burman) Chakma, Jamatia, Mog, Mizo, Tripuri, (Dravidian) Irula, Koya Dora, Kamar, Kota, Konda Reddy, Kurumba, Muria, Toda (Indo-European) Halba. The 18 castes include (Dravidian) Iyer, Iyengar, Ambalakarar, Vanniyar, Vellalar, Pallan and (Indo-European) Koknasth Brahmin, Uttar Pradhesh Brahmin, West BengalBrahmin, Rajput, Agharia, Gaud, Mahishya, Maratha, Bagdi, Chamar, Nav Buddha, Tanti. With exception of the Koya Dora and Konda Reddy groups, these samples have been previously described (Basu et al. 2003).J2 is divided into two main clades: J2a*-M410 and J2b*-M12:
New phylogenetic resolution has been achieved within the J2-M172 clade with the discovery of the M410 nucleotide A to G substitution (Table 2). Now all J2-M172 derived lineages can be assigned to one of two sister clades, namely J2a*-M410 and J2b*-M12, necessitating an updated revision of the previous “haplogroup by lineage” YCC nomenclature for J2 (Jobling et al. 2003). The J2*-M172 phylogenetic revisions are presented in supplemental dataA5. We include the DYS413≤18 allele repeat node in the phylogeny as suggested by Di Giacomo et al. (2004). It is notable that no J2*-M172 haplogroup lacking both M410 and M12 derived alleles has yet been observed. The DYS413 locus was typed in M410 derived samples from India, Pakistan and Turkey. The vast majority displayed the ≤18 allele repeat, although 16/118 in Turkey had alleles ≥19, as did 5/17 in Pakistan and 5/28 in India, 4 of which were restricted to the Dravidian-speaking Iyengar and Iyer upper castes.5 New Clades in haplogroups C, L, Q, and I:
We report 5 new clades that improve the haplogroup topology within the Y-chromosome genealogy. The new subclade C5-M356, accounts for 85% of the former C* haplogroups. While its overall frequency is only 1.4% in the Indian sample, it occurs in all linguistic groups, and in both tribes and castes. It also occurs in 1 Dravidian Brahui in Pakistan (Table 3). The new L3-M357 subclade which accounts for 86% of L-M20(xL1xL2) chromosomes in Pakistan; but occurs sporadically (3/728) in India. All Indian haplogroup Q representatives belong to the new M346-subclade. This new Q clade will aid in future studies attempting to narrow the candidate Asian/Siberian precursors of Native American chromosomes. The G5-M377 substitution is independent of G1-M285 and G2-P15 subclades (Cinnioglu et al. 2004) and occurs in Pakistan. The M379 polymorphism defines the I1c2 subclade, that occurs only our Pakistani data.Indigenous Indian haplogroups:
On the basis of the combined phylogeographic distributions of haplotypes observedR1a1 and R2:
among populations defined by social and linguistic criteria, candidate haplogroups that most plausibly arose in situ within the boundaries of present day India include C5-M356, F*-M89, H*-M69 (and its sub-clades H1-M52 and H2-APT), R2-M124 and L1-M76. The congruent geographic distribution of H*-M69 and potentially paraphyletic F*-M89 Y-chromosomes in India suggests that they might share a common demographic history.
The widespread geographic distribution of haplogroup R1a1-M17 across Eurasia and the current absence of informative subdivisions defined by binary markers leave its geographic origin uncertain. However the contour map of R1a1-M17 variance shows the highest variance in the northwest region of India (Figure 3).Clustering of R1a1 haplotypes:
...
In haplogroups R1a1 and R2 the associated mean microsatellite variance is highest in tribes (Table 8), not castes. This is a clear contradiction to what would be expected from an explanation involving a model of recent occasional admixture.
...
Specifically, they could have actually arrived in southern India from southwest Asian source region multiple times with some episodes being considerably earlier than others. Considerable archeological evidence exists regarding the presence of Mesolithic peoples in India (Kennedy 2000), some of whom could have entered the
subcontinent from the northwest during the late Pleistocene period. The high variance of R1a1 in India (Table 8), the spatial frequency distribution of R1a1 microsatellite variance (Figure 3) clines and expansion time (Table 7) support this view.
The ages of the Y-microsatellite variation (Table 7) for R1a1 and R2 in India suggest that the pre-historical context of these haplogroups will likely be complex. A PC plot of R1a1-M17 Y-microsatellite data (Figure 4) shows several interesting features: (a) one tight population cluster comprising S. Pakistan, Turkey, Greece, Oman and West Europe, (b) one loose cluster comprising all the Indian tribal and caste populations, with the tribal populations occupying an edge of this cluster, and (c) Central AsiaThe spread of J2a:
and Turkey occupy intermediate positions. The upper and lower bounds of the divergence time between the two clusters is 12 kya and 8 kya, respectively. The pattern of clustering does not support the model that the primary source of the R1a1-M17 chromosomes in India was Central Asia or the Indus valley via Indo-European speakers.
Figure 2 demonstrates the eastward expansion of J2a-M410 to Iraq, Iran and Central Asia coincident with painted pottery and ceramic figurines, well documented in the Neolithic archeological record (Cauvin 2000). Near the Indus valley, the Neolithic site of Mehrgarh beginning around 5000 BCE (Kenoyer 1998) displays the presence of these types of material culture correlated with the spread J2a-M410 in Pakistan. While the association of agriculture with J2a-M410 is recognized, it is not necessarily the only explanation for its history. Despite an apparent exogenous frequency spread pattern of hg J2a towards North and Central India from the west (Figure 2), it is premature to attribute it to a simplistic demic expansion of early agriculturalists and pastoralists from the Middle East. It reflects the overall net process of spread that may contain numerous as yet unrevealed movements embedded within the general pattern. It may also reflect a combination of elements of earlier prehistoric Holocene epi-paleolithic peoples from the Middle East, subsequent Bronze Age Harappans of uncertain provenance and succeeding Iron Age Indo-Aryans from Central Asia (Kennedy 2000). Further, the relative position of the Indian tribals (Fig. 4), the high microsatellite variance among them (Table 8), the estimated age (14 kya) of microsatellite variation within R1a1 (Table 7) and the variance peak in the west (Fig. 3) are entirely inconsistent with a model of recent gene flow from castes to tribes and a large genetic impact of the Indo-Europeans on the autochthonous gene pool of India. Instead, our overall inference is that an early Holocene expansion in NW India (including the Indus) contributed R1a1-M17 chromosomes both to the Central Asian and S Asian tribes prior to the arrival of the Indo-Europeans.J2a in upper caste Indians:
The J2 clade is nearly absent among Indian tribals, except among Austro-Asiatic speaking tribals (11%). Among the Austro-Asiatic tribals, the predominant J2b2 hg occurs only in the Lodha.
...
Haplogroup J2a-M410 is confined to upper caste Dravidian and Indo-European speakers, with little occurrence in the middle and lower castes. This absence of even modest admixture of J2a in south Indian tribes and middle and lower castes is inconsistent with the L1 data. Overall, therefore, our data provide overwhelming support to an Indian origin of Dravidian speakers.Haplogroup frequencies:

American Journal of Human Genetics (in press)
Polarity and Temporality of High Resolution Y-chromosome Distributions in India Identify Both Indigenous and Exogenous Expansions and Reveal Minor Genetic Influence of Central Asian Pastoralists
Sanghamitra Sengupta, Lev A. Zhivotovsky, Roy King, S. Q. Mehdi, Christopher A. Edmonds, Cheryl-Emiliane T. Chow, Alice A. Lin, Mitashree Mitra, Samir K. Sil, A. Ramesh, M.V. Usha Rani, Chitra M. Thakur, L. Luca Cavalli-Sforza, Partha P. Majumder and Peter A. Underhill
Abstract
While considerable cultural impact on social hierarchy and language in south Asia is attributable to the arrival of nomadic Central Asian pastoralists, genetic data (mitochondrial and Y chromosomal) have yielded dramatically conflicting inferences on the genetic origins of tribes and castes of south Asia. We sought to resolve this conflict using high-resolution data on 69 informative Y-chromosome binary markers and 10 microsatellite markers from a large set of geographically, socially and linguistically representative ethnic groups of south Asia. We have found that the influence of Central Asia on the pre-existing gene pool was minor. The ages of accumulated microsatellite variation in the majority of Indian haplogroups exceed 10-15 kya, attesting to the antiquity of regional differentiation. Therefore, our data do not support models that invoke a pronounced recent genetic input from central Asia to explain the observed genetic variation in south Asia. R1a1 and R2 haplogroups indicate demographic complexity that is inconsistent with a recent single history. Associated microsatellite analyses of the high frequency R1a1 haplogroup chromosomes indicate independent recent histories of the Indus valley and the peninsular Indian region. Our data are also more consistent with a peninsular origin of Dravidian speakers than a source with proximity to the Indus and significant genetic input resulting from demic diffusion associated with agriculture. Our results underscore the importance of marker ascertainment towards distinguishing phylogenetic terminal branches from basal nodes when attributing ancestral composition and temporality to either indigenous or exogenous sources. Our reappraisal indicates that pre-Holocene and Holocene era – not Indo-European – expansions have shaped the distinctive south Asian Y-chromosome landscape.
November 06, 2005
More on R1a1 age and haplogroup J2 in upper caste Hindus
A reader has brought to my attention a paper which appeared in 2001 in the Indian Journal of Genetics, and which is quite interesting for the discussion of the origins of haplogroup R1a1, as well as for the problem of the genetic makeup of the Proto-Indo-Europeans.
The Indian researchers have studied the microsatellite diversity of their northern Indian sample, and have estimated the corresponding age of haplogroup R1a1 (referred to as HG3). This age is 5,200 years. However, age is calculated based on assumptions about (i) the mutation rate, i.e., how fast microsatellites mutate, as well as (ii) the generation length. The 2001 paper makes assumptions which lead to an age that is 2.17 times younger than the assumptions of the recent South Siberian study. If we convert these estimates to the younger scale, we obtain ages of 5,193 years for Central Asia and 5,244 years for Eastern Europe. In other words, the age of R1a1 seems to be comparable in the three regions. The discrepancy of the ages in the two papers also underscores how the dating of prehistoric events depends to a great degree to assumptions which vary from researcher to researcher.
More fascinating is the finding that the main haplogroup distinguishing the northern Indian brahmins from the lower castes is J2 (referred to as HG9). I have long argued that haplogroup J2, associated with the early Neolithic expansions was also the PIE lineage par excellence, and this certainly supports this theory. It may very well be that in early times, the Indo-Iranians emerged as J2-bearing Indo-Europeans diffused into the R1a1-bearing east, with the resulting J2/R1a1 then settling on the Iranian plateau and invading India from the north.
UPDATE I:
The frequency of this haplogroup is highest (23.5%) among the upper-ranked caste Brahmin and is lower (17.1%) among the middle-ranked caste Rajput. It is known that after the entry of the Aryan speakers into India, the Brahmins were the torchbearers and promoters of Aryan rituals (Karve 1961). Therefore it is likely that this group had the highest genetic contact with the Aryan-speaking peoples. This observation is consistent with the high frequency of HG-9 observed among them. This haplogroup may have percolated into the middle-ranked Rajput either through admixture with Brahmins or directly with the Aryan-speaking immigrants. Since historians (Thapar 1975) have noted that some of the Central Asian pastoral nomads are ancestors of Rajputs, it is more likely that this haplogroup (HG-9) was introduced into the Rajputs directly by the Central Asians than indirectly through admixture with the Brahmins. It is noteworthy that HG-9 is absent among the low-ranked caste group, Chamar.
Interestingly though, in Oman the age of R1a1 is 11,400 years or 5,178 equivalent years using the same assumptions about generation length and mutation rate as above. In Iran and Pakistan it is 6,300 and 6,200 years old. Hence, all these ages seem very close to each other, and -given their confidence intervals- we cannot at present determine the point of origin of haplogroup R1a1.
UPDATE II:
Also of interest is Cordaux's extensive study of Indian Y chromosomes. Interestingly, the odds ratio for an Indian J2 being a caste vs. a tribal is 4 times more likely, whereas for an Indian R1a1 it is only 2.3 times more likely. This further supports the idea that haplogroup J2 significantly differentiates between Hindu caste members and indigenous non-caste populations. Unfortunately, Cordaux does not report differences within the Hindu caste hierarchy; it would be interesting to see whether J2 is even more prevalent among the upper castes within this hierarchy.
Journal of Genetics, 80(3): 125-135
High-resolution analysis of Y-chromosomal polymorphisms reveals signatures of population movements from Central Asia and West Asia into India
N. Mukherjee et al.
Abstract
Linguistic evidence suggests that West Asia and Central Asia have been the two major geographical sources of genes
in the contemporary Indian gene pool. To test the nature and extent of similarities in the gene pools of these regions we have collected DNA samples from four ethnic populations of northern India, and have screened these samples for a set of 18 Y-chromosome polymorphic markers (12 unique event polymorphisms and six short tandem repeats). These data from Indian populations have been analysed in conjunction with published data from several West Asian and Central Asian populations. Our analyses have revealed traces of population movement from Central Asia and West Asia into India. Two haplogroups, HG-3 and HG-9, which are known to have arisen in the Central Asian region, are found in reasonably high frequencies (41.7% and 14.3% respectively) in the study populations. The ages estimated forthese two haplogroups are less in the Indian populations than those estimated from data on Middle Eastern populations. A neighbour-joining tree based on Y-haplogroup frequencies shows that the North Indians are genetically placed between the West Asian and Central Asian populations. This is consistent with gene flow from West Asia and Central Asia into India.
Link
August 14, 2005
Population genetics of Indus Valley populations
A new article confirms that the genetic composition of the population of the Indo-Gangetic plain (Pakistan and NW India) consists of West Eurasian (Caucasoid) and indigenous South Asian elements. The contribution of other elements such as Sub-Saharan African in the Makrani "Negroids", the significant contribution of indigenous female South Asian elements to the Parsis (who are of Iranian origin, but live in India), and the contribution of Mongoloid elements in groups such as the Hunza, and the Hazara is also confirmed. The mtDNA distribution is shown below:

In terms of their Y-chromosome, the population of the region is of western Eurasian (Caucasoid) origin, also including a variant which has developed in the region and is found at lesser frequency elsewhere:
Update
For easier access, here is a break-down of Indian Y-chromosomal distribution taken from a recent comprehensive study (pdf).

And, a similar study on Y-chromosomal distribution from Pakistan (pdf):

Annals of Human Biology Mar-Apr 32(2):154-62.
A population genetics perspective of the Indus Valley through uniparentally-inherited markers.
McElreavey K and Quintana-Murci L.
Analysis of mtDNA and Y-chromosome variation in the Indo-Gangetic plains shows that it was a region where genetic components of different geographical origins (from west, east and south) met. The genetic architecture of the populations now living in the area comprise genetic components dating back to different time-periods during the Palaeolithic and the Neolithic. mtDNA data analysis has demonstrated a number of deep-rooting lineages of Pleistocene origin that may be witness to the arrival of the first settlers of South and Southwest Asia after humans left Africa around 60,000 YBP. In addition, comparisons of Y-chromosome and mtDNA data have indicated a number of recent and sexually asymmetrical demographic events, such as the migrations of the Parsis from Iran to India, and the maternal traces of the East African slave trade.
Link
{kind=link}
{kind=link}

In terms of their Y-chromosome, the population of the region is of western Eurasian (Caucasoid) origin, also including a variant which has developed in the region and is found at lesser frequency elsewhere:
In striking contrast to the mtDNA data, there is no strong evidence in Pakistani populations of Y-chromosome signatures of the early inhabitants of the region following the African exodus (Qamar et al. 2002, Zerjal et al. 2002), with their Y-chromosomes largely replaced by subsequent migrations or gene flow. The Y-chromosome gene pool of Pakistani populations is mainly attributable to western Eurasian lineages, particularly from the Middle East (Qamar et al. 2002). Conversely, few traces of East Asian haplogroups are observed in the Indus Valley populations. One Y-chromosome haplogroup (L-M20) has a high mean frequency of 14% in Pakistan and so differs from all other haplogroups in its frequency distribution. L-M20 is also observed, although at lower frequencies, in neighbouring countries, such as India, Tajikistan, Uzbekistan and Russia. Both the frequency distribution and estimated expansion time (~7,000 YBP) of this lineage suggest that its spread in the Indus Valley may be associated with the expansion of local farming groups during the Neolithic period (Qamar et al. 2002).
Update
For easier access, here is a break-down of Indian Y-chromosomal distribution taken from a recent comprehensive study (pdf).
And, a similar study on Y-chromosomal distribution from Pakistan (pdf):

Annals of Human Biology Mar-Apr 32(2):154-62.
A population genetics perspective of the Indus Valley through uniparentally-inherited markers.
McElreavey K and Quintana-Murci L.
Analysis of mtDNA and Y-chromosome variation in the Indo-Gangetic plains shows that it was a region where genetic components of different geographical origins (from west, east and south) met. The genetic architecture of the populations now living in the area comprise genetic components dating back to different time-periods during the Palaeolithic and the Neolithic. mtDNA data analysis has demonstrated a number of deep-rooting lineages of Pleistocene origin that may be witness to the arrival of the first settlers of South and Southwest Asia after humans left Africa around 60,000 YBP. In addition, comparisons of Y-chromosome and mtDNA data have indicated a number of recent and sexually asymmetrical demographic events, such as the migrations of the Parsis from Iran to India, and the maternal traces of the East African slave trade.
Link
August 08, 2005
Biogeographical Ancestry testing
John Hawks replies to some criticism of his earlier post by a blogger at Majority Rights. The subject is the meaning and usefulness of the DNA Print admixture test (AncestryByDNA).
First, we should distinguish between admixture testing in general, and the DNA Print family of tests in particular. Problems with the latter, e.g., "Native American" affiliation in Greeks, "South Asian" affiliation in Iberians, or "Middle Eastern" affiliation in the Irish do not invalidate the utility of admixture testing in general.
First, let's see how AncestryByDNA type tests work:
Frequency data of alleles are obtained for several reference populations, i.e., European, East Asian, Sub-Saharan African, and Native American. For example, if a locus X has three alleles, A, B, C then it is recorded that Europeans may have 50% of A, 30% of B, and 20% of C, while Sub-Saharan Africans may have 20% of A, 40% of B, and 40% of C. This type of frequency information is recorded for all alleles in all reference populations.
Next, individual genotypes are recorded for each customer. For example, for locus X, the customer may have allele C. This is the "hard" mechanistic part of the test, which is almost completely accurate.
Finally, the maximum likelihood estimate of admixture proportions is calculated. Suppose, for example that our hypothetical individual is 100% European and 0% Sub-Saharan African; the probability of observing a C is then simply 0.2, i.e., the frequency of C in the European population. If he is 100% Sub-Saharan African and 0% European, then this probability is 0.4. If he is 50% E/SSA then the probability is 0.5x0.2+0.5x0.4=0.3. All such admixture proportions are tested in a systematic, algorithmic way.
So, we see that the most likely ancestral composition of this individual is 100% Sub-Saharan African and 0% European, based on a single locus. The same kind of calculation can be used for multiple loci. As more loci are tested, the confidence in the admixture proportions increases; for example, the hypothetical individual presented above could quite easily be a European: after all, 60% of Africans do not have the C allele, whereas 20% of Europeans do. However, if we systematically observed that this individual had such common African alleles in multiple loci, then the probability that he had European admixture would be diminished.
So, admixture proportions depend on the following factors:
In some cases the "if" is justified. For example, the inhabitants of the Brazil can be reasonably seen as the product of admixture between Europeans, Native Americans and Sub-Saharan Africans, because these groups are known to have settled that country.
In other cases, this assumption is not justified. For example, South Asians are not the result of admixture between the four groups listed in the Ancestry By DNA test; this is established by the phylogeny of haploid markers such as mtDNA and the Y chromosome, which establish that South Asians have a high proportion of markers that are specific to themselves, e.g., South Asian-specific subclades of mtDNA macrohaplogroup M. So, South Asians are not reasonably modelled as the product of admixture between the four groups, because these four groups do not include a significant component in the ancestry.
It is important to see what is the problem here: any genotype will be assigned admixture proportions by the maximum likelihood estimation algorithms. Even a chimp's genotype would be assigned some proportions that add up to 100%. These proportions make sense only if the individual can be reasonably expected to be derived from the differentiated populations used as references.
This brings us to the second problem: which reference populations? For example, it is true that Europeans settled both Brazil and the United States, but not the same kind of Europeans. So, the frequency data from a pan-European or English sample do not represent the European component in Brazilians.
In conclusion, admixture testing works best when the parental populations are well-defined, highly differentiated and known to have historically admixed in a given territory. It does not work well when these conditions are not met.
Addendum
John suggests an alternative way of presenting the results of the test:
Certainly, it would be nice to have this type of information accompanying the haplotype results. However, this type of presentation can be deceptive. For example, many alleles have slight frequency differences in different human populations. For example, an allele may have a frequency of 50% in Africans and 40% in Europeans. We can certainly not be sure whether it is derived from a European or African ancestor: it is one of the alleles that are "common worldwide" in the quoted paragraph. However, the co-occurrence of many alleles of this kind carries information, and if an individual e.g., has 10 such alleles that are slightly more frequent in Africans than in Europeans and 3 that have the opposite pattern, then we can still conclude that African ancestry is highly probable.
Update
There is a discussion in Majority Rights blog which raises some objections to my comments. Let's address them one at a time:
This is completely irrelevant to my point. My point was that the genotype of a chimpanzee would have to be assigned to four numbers adding to 100%. That has nothing to do with the procedure used to obtain the genotype in the first place. Of course, we expect to have failed loci when we try to read a SNP in a different species, because primers developed for humans will not generally work in a different species; however, if we could read the letters in the 176 loci (or as many loci as are shared in the human and chimp sequence), and plugged the resulting genotype into the estimation algorithm, we would still get four numbers that add up to 100%.
In any case, one can repeat the example using an Australian instead of a chimp. An Australian's genotype would be assigned to the four groups with numbers adding to 100%, even though Australians cannot be viewed as being a mix of the four groups in question.
In other words, a population X may be genetically affiliated to East Asians either due to the joint possession of shared ancestral alleles, or due to the introgression of East Asian alleles into X. Someone labelled as e.g., 50% European + 50% East Asian according to DNAP may be for example (i) a first generation Japanese-Briton, or (ii) a Central Asian Turk of ancient Caucasoid-Mongoloid ancestry, or (iii) a South Asian. In cases (i,ii) he is the progeny of the admixture between Caucasoid and Mongoloid ancestors, whereas in case (iii) he is the progeny of Caucasoid and Proto-South Asian ancestors without any significant Mongoloid ancestry.
First, we should distinguish between admixture testing in general, and the DNA Print family of tests in particular. Problems with the latter, e.g., "Native American" affiliation in Greeks, "South Asian" affiliation in Iberians, or "Middle Eastern" affiliation in the Irish do not invalidate the utility of admixture testing in general.
First, let's see how AncestryByDNA type tests work:
Frequency data of alleles are obtained for several reference populations, i.e., European, East Asian, Sub-Saharan African, and Native American. For example, if a locus X has three alleles, A, B, C then it is recorded that Europeans may have 50% of A, 30% of B, and 20% of C, while Sub-Saharan Africans may have 20% of A, 40% of B, and 40% of C. This type of frequency information is recorded for all alleles in all reference populations.
Next, individual genotypes are recorded for each customer. For example, for locus X, the customer may have allele C. This is the "hard" mechanistic part of the test, which is almost completely accurate.
Finally, the maximum likelihood estimate of admixture proportions is calculated. Suppose, for example that our hypothetical individual is 100% European and 0% Sub-Saharan African; the probability of observing a C is then simply 0.2, i.e., the frequency of C in the European population. If he is 100% Sub-Saharan African and 0% European, then this probability is 0.4. If he is 50% E/SSA then the probability is 0.5x0.2+0.5x0.4=0.3. All such admixture proportions are tested in a systematic, algorithmic way.
So, we see that the most likely ancestral composition of this individual is 100% Sub-Saharan African and 0% European, based on a single locus. The same kind of calculation can be used for multiple loci. As more loci are tested, the confidence in the admixture proportions increases; for example, the hypothetical individual presented above could quite easily be a European: after all, 60% of Africans do not have the C allele, whereas 20% of Europeans do. However, if we systematically observed that this individual had such common African alleles in multiple loci, then the probability that he had European admixture would be diminished.
So, admixture proportions depend on the following factors:
- Individual genotype
- Parental reference populations
In some cases the "if" is justified. For example, the inhabitants of the Brazil can be reasonably seen as the product of admixture between Europeans, Native Americans and Sub-Saharan Africans, because these groups are known to have settled that country.
In other cases, this assumption is not justified. For example, South Asians are not the result of admixture between the four groups listed in the Ancestry By DNA test; this is established by the phylogeny of haploid markers such as mtDNA and the Y chromosome, which establish that South Asians have a high proportion of markers that are specific to themselves, e.g., South Asian-specific subclades of mtDNA macrohaplogroup M. So, South Asians are not reasonably modelled as the product of admixture between the four groups, because these four groups do not include a significant component in the ancestry.
It is important to see what is the problem here: any genotype will be assigned admixture proportions by the maximum likelihood estimation algorithms. Even a chimp's genotype would be assigned some proportions that add up to 100%. These proportions make sense only if the individual can be reasonably expected to be derived from the differentiated populations used as references.
This brings us to the second problem: which reference populations? For example, it is true that Europeans settled both Brazil and the United States, but not the same kind of Europeans. So, the frequency data from a pan-European or English sample do not represent the European component in Brazilians.
In conclusion, admixture testing works best when the parental populations are well-defined, highly differentiated and known to have historically admixed in a given territory. It does not work well when these conditions are not met.
Addendum
John suggests an alternative way of presenting the results of the test:
Compare to this hypothetical result, based on alleles only without any reference to Linnaean taxonomy. The person is told he has 89 alleles that are common worldwide, 35 that are common in Europe but rare elsewhere, 4 that are very common in East Africa and moderately common in the Near East, 10 that are very common in China and Thailand, moderately common in India and Pakistan, and present but less common in the Near East, and 2 alleles that are very high frequency in Native Americans, but also present in Siberia, Caucasus, the Near East, and Greece.
Certainly, it would be nice to have this type of information accompanying the haplotype results. However, this type of presentation can be deceptive. For example, many alleles have slight frequency differences in different human populations. For example, an allele may have a frequency of 50% in Africans and 40% in Europeans. We can certainly not be sure whether it is derived from a European or African ancestor: it is one of the alleles that are "common worldwide" in the quoted paragraph. However, the co-occurrence of many alleles of this kind carries information, and if an individual e.g., has 10 such alleles that are slightly more frequent in Africans than in Europeans and 3 that have the opposite pattern, then we can still conclude that African ancestry is highly probable.
Update
There is a discussion in Majority Rights blog which raises some objections to my comments. Let's address them one at a time:
2. Dienekes’ labelling of certain DNAP results as “problems” is, in my opinion, not justified without further evidence. Given that “Middle Eastern” in the Irish does NOT imply any sort of direct admixture of Middle Easterners (at least, as they exist today) into the Irish genepool, how it is known a priori that this is a problem?It is certainly a problem to claim that the Irish have more MIDEAS affiliation than the Turks. It goes against geography, history, physical anthropology and common sense. Until a satisfactory explanation for this unexpected result is offered, we are justified to view it as a bug of the test.
I have discovered that Dienekes is incorrect about the chimp comment. From http://www.dnawitness.net we see:-
Number of failed Loci
Chimpanzee - 157 out of 176 Gorilla - 151 out of 176 Orangutan - 137 out of 176”
This is completely irrelevant to my point. My point was that the genotype of a chimpanzee would have to be assigned to four numbers adding to 100%. That has nothing to do with the procedure used to obtain the genotype in the first place. Of course, we expect to have failed loci when we try to read a SNP in a different species, because primers developed for humans will not generally work in a different species; however, if we could read the letters in the 176 loci (or as many loci as are shared in the human and chimp sequence), and plugged the resulting genotype into the estimation algorithm, we would still get four numbers that add up to 100%.
In any case, one can repeat the example using an Australian instead of a chimp. An Australian's genotype would be assigned to the four groups with numbers adding to 100%, even though Australians cannot be viewed as being a mix of the four groups in question.
4. Dienekes’ comments about South Asians disregard the Euro 1.0 test.The EURO-DNA test measures the "South Asian" component of the "European" component. However, I was not referring to the "South Asian" component of the "European" component, but to the aboriginal South Asian component which is _not_ related to the Western Eurasian (Caucasoid) component, and is evidenced primarily by the predominance of extremely ancient South Asian specific clades of mtDNA macrohaplogroup M. In short, with the exception of some Mongoloid tribes, South Asians are not descended from East Asians (Mongoloids). They are descended from very old indigenous South Asian populations as well as more recent Central Asian (Caucasoid) populations. Whatever similarity they have with East Asians is due to common ancestry _before_ the emergence of Mongoloids.
In other words, a population X may be genetically affiliated to East Asians either due to the joint possession of shared ancestral alleles, or due to the introgression of East Asian alleles into X. Someone labelled as e.g., 50% European + 50% East Asian according to DNAP may be for example (i) a first generation Japanese-Briton, or (ii) a Central Asian Turk of ancient Caucasoid-Mongoloid ancestry, or (iii) a South Asian. In cases (i,ii) he is the progeny of the admixture between Caucasoid and Mongoloid ancestors, whereas in case (iii) he is the progeny of Caucasoid and Proto-South Asian ancestors without any significant Mongoloid ancestry.
Subscribe to:
Posts (Atom)